
One-in-15-Million Flight Plan Causes UK Air Traffic Chaos
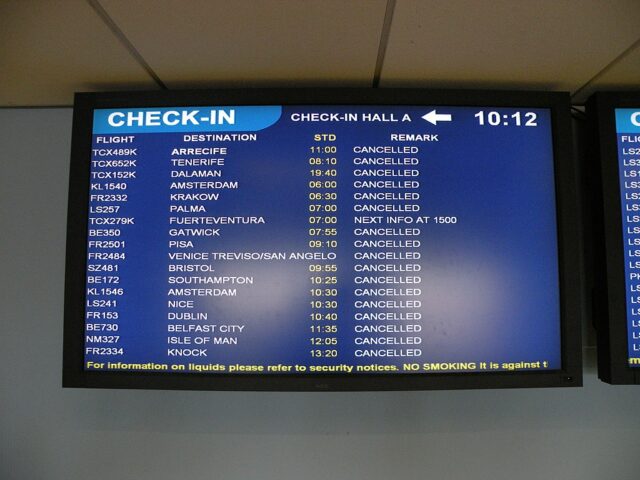
On Monday, the 28th of August 2023, a “technical glitch” in the National Air Traffic Services (NATS) in the UK caused extensive flight delays and cancellations. Monday was the Late Summer Bank Holiday, which takes place the last Monday in August for a long weekend at the end of the summer season. As a result of the fault, the airspace around the United Kingdom remained open; however Air Traffic Control could not automatically process flight plans. The increasing stress as they tried to restore the systems and deal with flight plans manually became apparent through the updates from NATS during the day (all times are UK local):
12:10 We are currently experiencing a technical issue and have applied traffic flow restrictions to maintain safety. Engineers are working to find and fix the fault. We apologise for any inconvenience this may cause. Please check with your airline on the status of your flight.
12:40 We are continuing to work hard to resolve the technical issue. To clarify, UK airspace is not closed, we have had to apply air traffic flow restrictions which ensures we can maintain safety.
14:20 This morning’s technical issue is affecting our ability to automatically process flight plans. Until our engineers have resolved this, flight plans are being input manually which means we cannot process them at the same volume, hence we have applied traffic flow restrictions. Our technical experts are looking at all possible solutions to rectify this as quickly as possible.
Our priority is ensuring every flight in the UK remains safe and doing everything we can to minimise the impact. Please contact your airline for information on how this may affect your flight. We are sincerely sorry for the disruption this is causing.
15:15 We have identified and remedied the technical issue affecting our flight planning system this morning. We are now working closely with airlines and airports to manage the flights affected as efficiently as possible. Our engineers will be carefully monitoring the system’s performance as we return to normal operations.
The flight planning issue affected the system’s ability to automatically process flight plans, meaning that flight plans had to be processed manually which cannot be done at the same volume, hence the requirement for traffic flow restrictions. Our priority is always to ensure that every flight in the UK remains safe and we are sincerely sorry for the disruption this is causing. Please contact your airline for information on how this may affect your flight.
Two days later, the technical issue which led to thousands of flight cancellations and delays across the UK, was rather vaguely identified as a single flight plan.
Initial investigations into the problem show it relates to some of the flight data we received. Our systems, both primary and the back-ups, responded by suspending automatic processing to ensure that no incorrect safety-related information could be presented to an air traffic controller or impact the rest of the air traffic system. There are no indications that this was a cyber-attack.

The media response was a mix of disbelief and outrage. The Director General of the International Air Transport Association was scathing:
This incident is yet another example of why the passenger rights system isn’t fit for purpose. Airlines will bear significant sums in care and assistance charges, on top of the costs of disruption to crew and aircraft schedules. But it will cost NATS nothing. The UK’s policy makers should take note. The passenger rights system needs to be rebalanced to be fair for all with effective incentives. Until that happens, I fear we will see a continuing failure to improve the reliability, cost efficiency, and environmental performance of air traffic control.

But over on the Professional Pilots Rumour Network (PPRuNe), there were a few industry voices who pointed out that this was not as far fetched as it might seem. The flight plan for the flight inbound to the UK cannot simply have been malformed: that would have been rejected by Eurocontrol, the Brussel’s based intergovernmental organisation that coordinates flight plans and air traffic control above 24,500 feet over Belgium, Luxembourg, the Netherlands and north-west Germany. 80% of their traffic is climbing from or descending to major European airports, including London. Further, flight plans are run through simple filters set up on the UK systems, with a malformed flight plan marked as requiring manual entry. The fact that the flight plan to make it past these initial checks and yet was able to disrupt the entire system pointed to a hitherto unknown bug in the complex software used in the UK.
For example, on the 12th of December 2014, a NATS system failure led to all departures being stopped from London Airports as well as flights departing European airports which planned to route through UK airspace. The software engineers may be interested in reading the full final report of the independent enquiry which explains the full context of this “latent software fault that was present from the 1990’s”.
The System Flight Server software determined the number of Controller and Supervisor roles, which were known as Atomic Functions, in order to distribute data to the relevant roles. The maximum of civil and military Atomic Functions was designed to be 193, a number that everyone was aware was a limit. However, when generating a table of the current Controller and Supervisor roles, the check against the maximum size of the table (that is, the maximum number of Atomic Functions) tested against the civil limit, which was 151. As it happened, this didn’t much matter on a day-to-day, and there was nothing to alert anyone to the fact that this check was against the wrong maximum figure until the 12th of December.
The day before the outage, the system was changed to include further military Controller roles, which meant the (incorrect) limit of 151 was now being exceeded. Then, a controller set his workstation to the wrong mode. Usually, workstations are left “signed on” when unattended so that they are available to be used. However, this controller accidentally set his workstation into Watching Mode, an obsolete mode which staff were apparently regularly accidentally selecting. Again, this on its own didn’t much matter. However, Watching Mode triggers the System Flight Server to generate a table of the Atomic Functions (all current controller and supervisor roles). There were 153 entries in the table, which exceeded the permitted maximum size of the table, which was set to 151. This led to a series of system failures that culminated in a complete system collapse.
A PPRuNe poster identified as Engineer39 wrote about the practical limits of failure testing:
I was one of the people who signed off the upgrade in 2014 as being OK to implement. We were right as it was safe, just not resilient.
As the linked report here show it was all due to the 154th workstation being turned on and crashing the system. Of course some may say “How can NATS be so stupid as to not spot this and test for it?” Well the test suite has around 90 workstations so there is no way you can turn on 154 stations to test the software past its 153 limit. And no chance of getting time in >100 ATCOs’ schedule to get them all to come in and exercise all the stations even if you had >153 to test. And you can’t test on the live system with it many stations, as of course it’s not possible to find space in the schedule to do this on a system that is live 24/27/365. So it instead relies on software engineers understanding code that was rewritten >10 years before to understand what the 153 number meant. Obviously in that case no one understood it, or if they did, thought it meant active stations and forgot about the ones in a half on state. It’s not possible to retain all the knowledge from years ago unless no one resigns, retires or is made redundant. And you don’t outsource anything.
All in all I can’t see practically how that incident could have been avoided.
I have no knowledge on this new incident but suspect the causes are all rather similar and that practically it should be possible to eliminate this particular case from happening again, but you can’t say “We will never have a crash again”.
Upgrading it all to a brand new software may help long term but likely there will be more short term disruption due to new bugs introduced.
I think NATS compares very favourably in disruption compared with other ASNPs. But some (small) improvements will hopefully come out of all this.
Another poster, Murty, offered a more specific example of how a flight plan might cause a software disruption. In this case, it is the Aeronautical Fixed Telecommunication Network (AFTN) that causes the problem. The Aeronautical Fixed Telecommunication Network allows for messages between fixed stations, including Air Navigation Services, aviation service providers, airport authorities and government agencies. An AFTN message has three parts: a heading, the message text, and an ending.
The message text is in plain text and ends with an End-of-Message Signal, which is the four characters NNNN.
Murty says that as a result, the UK system trips over any call sign with NNN in it, which they have had to work around. He says so far, only two aircraft out of three have tripped the system.
DC Aviation have C56X registered DCNNN but flies under the fixed callsign DCS705
JYNNN C172 was delivered to Bournemouth back in 2020 ,and tripped our system (which was rectified fairly quickly)
MNNNN Gulfstream 6: this was registered by a Russian on 16/7/2014,it became a regular visitor to the UK and I became involved with many e-mails with the Operator, pointing out that their ID was going to be a problem at all airports as the Flight Plan could not reach addresses STOPPING after MNNNN. The owner reregistered the aircraft MNGNG
The fact our system stops after 3 N’s is strange
Other counties have quirks the FAA system does not like callsigns begining with a number with number. I was advised by a coleague in FAA while carrying out an investigation, which is strange with Barbados (8P-). This may have been notice at airports with 8P-ASD Gulfstream 6, which will often file as “X8PASD”, as does the Malaysian Gov 9MNAA A320 that file with a letter.
But my favourite example of all was an outage of ATC software in Los Angeles in 2014.
The En Route Automation Modernization (ERAM) system was designed by Lockheed Martin. Introduced in 2011, by 2018 the FAA stated that ERAM was managing over 3 million high-altitude en-route aircraft every month.
In April 2014, a flight plan crashed the system, causing Los Angeles Center to suspend all operations and clear the Center’s airspace, including a ground stop at Los Angeles International Airport. 365 flights were cancelled and over 400 delayed during the two-hour outage. At the time, ERAM did not have a dedicated backup system as the FAA believed that the dual channel design provided enough redundancy.
What happened? ERAM not only tracks the current flights but also looks ahead, searching projected course, speed and altitude for potential conflicts between aircraft.
A flight plan was submitted for a military aircraft carrying out a surveillance training mission.

But this wasn’t just any military aircraft. It was the famous high-altitude reconnaissance aircraft U-2, coincidentally also designed and produced by Lockheed some time earlier. The training mission had the aircraft entering and leaving the control zone repeatedly, with a flight plan that came close to the maximum data that ERAM can accept. However, the flight plan didn’t include the altitude. Apparently, a controller at a neighbouring system attempted to add in an altitude of 60,000 feet but made some sort of data entry error. Some sources say that ERAM believed that the U-2 was repeatedly flying through the control zone area at high speed at 7,000 feet. Another source says that ERAM treated the U-2 as flying every altitude between ground level and infinity.
Either way, ERAM attempted to consider all possible conflicts caused by the spy plane racing in and out of Los Angeles airspace. This quickly used all of the available memory. Finally, the flight data memory overloaded and both ERAM channels failed. In actuality, the U-2 was safely above the traffic at 60,000 feet.

Earlier this week, NATS released a Major Incident Preliminary Report which sheds some light on what happened. The report explains that aircraft flying through European countries submit flight plans, including aircraft type, speed and routing, to Eurocontrol. If Eurocontrol’s processing system accepts the flight plan, it is sent to all relevant Air Navigation Service Providers, including NATS in the UK.
Within NATS, the data goes to a system called Flight Plan Reception Suite Automated Replacement (FPRSA-R), which converts the data into a format compatible with the UK National Airspace System (NAS). Effectively, this modern system processes and sanitises the flight planning data before passing it on to more critical systems.
On 28 August, an airline submitted a flight plan for a flight departing at 04:00. NATS received this flight plan at 08:32, consistent with the 4-hour rule before the aircraft enters UK airspace. The flight plan was converted from ICAO4444 format to ADEXP, which includes additional waypoints. However, this specific flight plan had two waypoints with the same designator.
Now, I always thought that waypoint names, a five-letter designator for specific geographic coordinates used for routing flights, were unique. However, as pilots with more international experience than I have will already know, they are not globally unique. As long as they are “geographically widely spaced,” this was not seen to be an issue. When entering a waypoint for flight planning, pilots simply check the distance to make sure they had selected the right version of the waypoint. It is extremely rare for a single route to include two waypoints that share the same name.
However, whether due to changes in aircraft flight data systems or the result of longer flights, this particular flight plan apparently (and correctly, it seems) had two waypoints with the same identifier. The two waypoints were about 4,000 nautical miles apart and both were outside of UK airspace. FPRSA-R attempted to extract the UK portion of the flight from the flight plan. First, it searches to find the entry waypoint and then it works backwards, parsing from the end of the flight plan, in order to determine the exit waypoint. If the exit waypoint isn’t listed, then the nearest waypoint beyond the UK is chosen as the exit point. However, the system was unable to make sense of two waypoints having the same name, presumably confused by finding an exit waypoint in a context that didn’t make geographic sense.
When the software failed to logically determine the entry and exit points, it raised a critical exception. As a part of the fail-safe, the primary system went into maintenance mode rather than risk passing incorrect data to air traffic controllers. The back-up system took over the task and (you can probably see this coming) when it attempted to convert the data, it equally could not find the entry and exit points and so it also raised a critical exception and went into maintenance mode.
The time elapsed between receiving the problematic flight plan and both systems shutting themselves down was less than twenty seconds.
After both systems shut themselves down, the 24/7 on-site support team attempted to diagnose the issue. They quickly escalated to their second-line support team of on-call experts. When both teams failed to pinpoint the root cause or restore the service, they called in the Technical Design team and the manufacturer of the software, which seems to be Frequentis Comsoft. The manufacturer was able to identify the problematic flight plan and devise a recovery plan. Once the system was reinstated, the next four hours of flight plans were processed in about nine minutes.
The NATS preliminary report states that if a flight plan with these characteristics had previously been filed, it would have caused the same issue. This system was updated in 2018 with new hardware and software and has processed over 15 million flight plans since then without a dual system loss; thus, the chief executive of NATS called it a one-in-15-million flight plan. The good news, said the chief executive, is that the system did what it was designed to do, i.e. fail safely when it receives data that it can’t process
However, next week’s software changes will hopefully remove the need for a critical exception in similar circumstances. NATS have also promised further investigation to see if the circumstance could have been prevented during the software development cycle.
The Civil Aviation Authority has confirmed that the technical event has been understood and that, if it were to reoccur, it would be fixed quickly without affecting flights. They will oversee the NATS investigation and in addition, they will be initiating an independent review of the technical failure and the response.







It seems a little odd. I’ve written some flight planning software myself (for simulation only, not for real use!) and the non-uniqueness of waypoint IDs was one of the first things that came up, because if I’m converting a list of points to lat/long positions (for display, routeing, etc.) I need to know which point I’m looking at. Answer: find the nearest matching point to previous/next points in the plan, maybe raise a query if they’re a long way apart., but obviously don’t use the waypoint ID as a unique key, because you know it isn’t.
Once you’ve worked out the algorithms to do that, it seems pretty obvious that you’d include a test case to handle this specific situation – and I assume something like the NATS software has a lot of test cases!
So speaking as a coding professional in rather less safety-critical fields, that this should be a problem argues for some fairly poor coding/testing technique.
I’ll bet a steak dinner that this wasn’t known to the original developers, and I’ll bet once it was discovered, it was assumed no correct flight plan will include 2 waypoints with the same ID “because they’re so far apart” and since it was originally assumed waypoint IDs were unique, no tests were designed against this issue.
I deal with trash coding and testing practices like this on a daily basis, and it takes up a good chunk of my time.
One recent system assumed it could see GPS satellites all the time and completely fell over when it was tested in an old hangar with a heavy metal roof. Other systems assume they have constant internet access and completely fail if they don’t have an assigned IP address, despite the network having no bearing on their actual function.
It’s not much different from https://www.kalzumeus.com/2010/06/17/falsehoods-programmers-believe-about-names/
Heck, one of my testers in my org has a British-style hyphenated last name, and the user ID systems in my org constantly lose their shit over this. She’s constantly batting someone, trying to get them to fix a computer account somewhere that’s rejecting her name.
And you’re assuming all those test cases are good, useful test cases that aren’t a total waste of testing resources.
A LOT of developers are just useless idiots. I’ve had to deal with “developers” that refused to “waste resources on sanity-checking input because the input will ALWAYS be correct” and it took me a long time to get him fired.
Careful now, we have a lot of developers here! Maybe “some” rather than “a lot” ? #notalldevelopers
ETA: By the way, I agree that it is very feasible that the software engineers presumed that waypoints were distinctly identified; you’d have to think to ask the question.
Agreed. It’s the kind of thing that a nomenclature designed by software developers would try hard to use, because it simplifies things.
As a developer/architect myself, I’d go with “a lot”!
As with the accident investigations featured on this blog, there’s generally many factors beyond one individual’s actions that lead to an incident.
As a developer myself, I’d go with “a lot of developers work in environments with time and money pressures, insufficient support for professional development, and managerial issues”.
One of the things that impressed me about this incident is that NATS has a 4-hour backup of flight plans that controllers could access. It took the technicians exactly 5 hours and 4 minutes to get the FPRSA-R system working again (and a further 51 minutes of testing before returning it to fully automated live operations); if the technicians had been able to identify the malfunction sooner, manual entering of flight plans could’ve been avoided altogether.
As I understand it from the preliminary report, the original flight plan as filed by the airline in ICAO4444 format did not contain duplicate waypoints. Eurocontrol converted the flight plan to ADEXP format, which adds more waypoints to the route, and apparently introduced the pair of duplicate waypoints separated by 4000 nautical miles. And when the system planned for the aircraft to potentially leave UK airspace at a point on another continent, it correctly diagnosed that something had gone wrong, and stopped. That’s not ideal, but at least it’s safe.
Besides the FPRSA-R failure itself, there were no reportable “safety related occurrences” during the incident. The system had reduced capacity for a while, but operated safely throughout. It’s very comforting to see that NATS’s priority is squarely on safety. If NATS Plc was made financially responsible for delays and cancellations caused by their systems, then that priority would be compromised. Nobody should want that.
Ah hah! I was clearly working too quickly — I had grasped that it was added by software at some stage but not that it happened in the conversion to ADEXP. Thanks for clearing that up.
As a software engineer of real-time embedded systems in avionics I am perplexed by why these two systems did not report the specific flight plan that caused the issue to the “maintenance” teams with an “error code” denoting that there was a conflict between waypoint identifiers?
Ironically, I worked with some of the software engineers who wrote these systems for NATS prior to them leaving GEC Avionics when we were all writing the code for HUDs in what was “Airborne Displays Division”.
In “my days” fight planning was relatively simple. Using the available Jeppesen charts, we would plot a route following the established airways.
They were colour-coded and numbered (e.g. Amber 5, Blue 6) and followed nav aids: Usually marked by VOR or ADF.
We would fill in the sheet and deposit it with AIS at least half an hour before departure.
High level started at FL 290. Flight above that would be subjected to 2000 feet vertical separation, so eastbound FL 290, FL330, FL370 etc.
Westbound flight therefore was at FL310, FL350, FL390 and so on.
And then, suddenly, there was an explosive tencholgical advancement, followed in its footsteps by an increase in air trafffic. Budget airlines were directly involved in this development.
But years before Dr. Tony Ryan had given the reins of Ryanair to Michael O’Leary, the changes started to manifest already
At first on long-haul flights the INS was replacing Loran, Decca and Doppler navigation systems. The Omega network of ultra-long wave stations gave rise to the introduction of VLF-Omega.and, nearly all of a sudden, enabled aircraft ot fly parallel tracks and use virtual waypoints. The accuracy of instruments like the Rosemount probe gave aircraft – and ATC – a means to access enhanced measurements of the density altitude in the rarified air at high altitude, and with it the real altitude.
Already the explosive increase of air travel, encouraged by the budget airlines, made it inevitable that modern navigation methods would be introduced and made mandatory. FMS was at first based mainly on VOR-DME, but once GPS became widespread there was absolutely no way that crew of private jets could compute their own nav plans. That became the preserve of specialised companies.
Likewise, at virtually all airports the use of handling agents became mandatory.
The introduction of RVSM airspace put more aircraft in the sky, more pressure on ATC and the computer systems that allowed controllers to keep all the balls up in the air.l
Of course, the system has become so complex that a relatively small “glitch” has a knock-on effect that cascades down on the entire affected airspace.
My own daughter was caugth up in the melee. It took her over three days to get from Amsterdam to Dublin.
Now, the following is pure speculation and possibly borderline nonsense, but I have this nagging feeling that Brexit has had a negative effect on the efficiency of NATS when it comes to something like this.
Would it have been technically possible for the Eurocontrol centres to pick up some of the slack?
I know that the ATC centres always operate very efficiently when it comes to handing over aircraft from one centre to another.
But I have a suspicion that on a more basic level, e.g. the integration of the airway charges: a financial consideration, Brexit may have caused a gap in the ability for Eurocontrol to step in and take over from some of the malfunctioning computers.
Is anyone more au fait than I am with this aspect?
I’m basing this reply on the preliminary report.
FPRSA has existed for many years, and its current incarnation, FPRSA-R, was installed in 2018, and thus predates Brexit. Its function is to convert the ADEXP flight plan into a format that the UK National Airspace System (NAS) can use.
I doubt Eurocontrol has systems that can do that; and if it did, they’d be the same systems as in Swanwick, with the same bug. There was simply no way for Eurocontrol to provide flight plans to NAS without a working FPRSA. But it also made no sense to relieve UK flight controllers of their duty.
What had to be done was to enter flight plans into NAS manually, and to coordinate between sectors manually. This increased the workload on the ATC Operators, so traffic had to be reduced to guarantee safety under these conditions, and that caused the delays/cancellations. The forecast was for ~7500 flights to be processed on August 28, but “only” ~5600 flights were actually processed. (And 575 flights were delayed by ~2 hours on average.) I don’t think Eurocontrol could’ve achieved a better result.
Mendel,
Thank you for your clarification.
Computers are boxes filled with “PFM”, as a ground instructor put it when he described the electronics of a type of aircraft that we were being made familiar with.
His description of the system consisted of a few lines and rectangles.
The lines connecting these rectangles were named “gozinta ” and “gozouta”: the current / signal goes inta here and goes outa there.
When it is in the “black box”, represented in his schematic by the rectangles, he told us that they were full of “PFM”, pure f..ing magic.
Get my drift? What you cannot do anything about if it breaks during the flight is not anything that you need to know more about.
What we did have to learn, of course, is how the aircraft could cope if the PFM stopped performing. Both in the classroom, and in the simulator.
Just as well, because I managed to cope, going over the emergency checklist, but to me a computer still is a “confuser”.
And so, in my naivity, i thought that ATC confusers in other jurisdictions (Eurocontrol) may have had the capacity and capability to link up with NATS to form a chain and at least mitigate the problem.
But obviously not.
Yes.
The PFM linking Eurocontrol and the UK NAS had broken (and so had the backup box), but NATS had an emergency checklist that they had trained for, and so they safely coped until the wizards put the magic back. ;)
Being a software Engineer, I should say that what Engineer39 says is sheer nonsense or (I hope) an incorrect quote. No serious test Engineer should say : “Well the test suite has around 90 workstations so there is no way you can turn on 154 stations to test the software past its 153 limit. And no chance of getting time in >100 ATCOs’ schedule to get them all to come in and exercise all the stations even if you had >153 to test”. When testing a system you do not use the actual input/output devices (in this case 90 workstations and I presume, some staff), because usually they are not available, but essentially, test results cannot be replicated. And this is the essence of the test: prepare a battery of test scenarios in such a way that any test can be replicated. If a test fails, this specific scenario is ran again, to check that this error has been corrected. But, this is not all, because any software modification may affect other modules, so, before putting the modified software into operation the full battery of tests must be passed again. This is called “Non-Regression” tests and its aim is to avoid the dreaded phrase that we have all hear sometime: “But… this worked yesterday”
As someone who did QA-ish work for a decade before moving to development, I am … unimpressed … with the statement that the developing agency didn’t have enough gear on hand to simulate a fully-occupied system. That might have passed muster 40 years ago, when deskside systems cost ~$30,000; powerful PCs have been so cheap in recent decades that the contractor should have gotten a full-sized testbed. (Carlos Griell touches on another approach, but is right that just throwing up your hands and ignoring the problem is not acceptable. For some reason my last employer called our suite “regression” tests rather than “non-regression”, but it had the same object; our core design product was up to ~24,000 of them by the time I got re-org’d out of a job, and I had shown there were areas which needed either manual testing with every internal version or a more powerful testbed — simulations involving multiple systems are not easy. But as Carlos points out, the comment from “Engineer39” is appalling.)
I’m also unimpressed with the lack of fault tolerance in a critical system; at the very least, it should have sounded klaxons in several sites as a signal that it was refusing to process a plan it couldn’t parse. That nobody knew that waypoint IDs weren’t unique is vaguely plausible (who assigns these IDs?) but that they didn’t have a way of saying “You are false data” without exploding immediately afterwards is very bad practice — this is the real world, not Dark Star(*). (Guy Hall’s comment touches on this.)
Sylvia: “an airline submitted a flight plan for a flight departing at 04:00. NATS received this flight plan at 08:32, consistent with the 4-hour rule before the aircraft enters UK airspace.” I’m not making sense of this; are the two times swapped, or was the plan filed 19.5 hours ahead of time?
Mendel: How do other countries handle connections to Eurocontrol (which Sylvia describes as covering only a small part of Europe)? Does each country do its own reinterpretation of a flight plan, or is that a British twist only?
Sylvia: wrt slamming other engineers: one of the unfortunate effects of job mobility is that people don’t usually stay around long enough to have to come back to their own code enough years later that they can see what they did wrong. I did — because I had 18 years in my last job; it’s a humbling experience. Whether I was right to have said “I’d never do something that stupid!” about some of the bugs I found in other people’s code is something I’ll never know (unless somebody comes up with a way to look at alternate worlds…).
(*) the 1970’s SF ~comedy movie, not the Grateful Dead piece.
4:00 Departure
8:32 Flight plan transmitted to NATS
12:32 aircraft enters UK airspace
For a flight exceeding 4000 nm to take more than 8½ hours doesn’t seem unusual.
I don’t know more about Eurocontrol than what the incident report provided, I’m sorry.
Yeah, the four am start with the four hour rule is a bit weird. I had to think about that one but I should have broken it down in the text once I’d grasped it.
To answer the one question in there that I can: the waypoints are actually created by airports and regions. In the US, the FAA has defined the standard and you have to stay in line with that. The person designing the approach (or whatever) can draw names from a pool of unique (but meaningless) waypoint names or they can requisition locally significant names, which they will get if the waypoint name isn’t already used elsewhere in the US. This is why you get some of the very silly name collections on some approaches. Expanding this on a country-by-country basis, it’s clear that it quickly gets unoverseeable.
Maybe I was exposing my lack of understanding of computer systems. It is real, but I was deliberately overstating my “luddite” status.
I hoped that it would help to elicit comments and it seems that it did – a lot of them actually – that are very interesting and educational.
So thanks to all those computer nerds ;-) who reacted.
I feel like I could do another post based on the comments to this one alone.
Another question: why does ADEXP add waypoints? ISTM that there’s no guarantee that those waypoints would be accurate; would an inbound aircraft be directed to deviate from its course to pass over added waypoints? Do the additions include vectors from the points to the actual flight path? Given modern air navigation, a path to point X doesn’t necessarily go through points A, B, …. I’ll be interested in what the final report has to say whenever it comes out.
I would think more likely that the point is to create that path clearly, so that the route to point X is unambiguous. But I’m guessing, I really don’t know.
See for example the flight plan EGHI ETRAT UN859 LGL A34 BENAR UN859 GAI B31 PUMAL UN859 GARBI LEPA (map at https://flightplandatabase.com/plan/6903717 ).
UN859, A34 and B31 are routes. The flight plan says to use route UN859 between ETRAT and LGL, and between BENAR and GAI, and between PUMAl and GARBI. That means ATC can’t just go, “they’re flying UN859”, they need to know the exact waypoints. Now imagine an ATC monitor with all the waypoints. There are a few “corners” on UN859 between BENAR and GAI, so the French ATC system would need to show these corners to the ATCOs to help them determine whether the aircraft deviates from its route. For that reason, the waypoints on those route segments need to be determined at some point in the process.
And when you do that for the UN859 segment between ETRAT and LGL, the waypoint DVL (Deauville) appears, duplicating DVL as Devil’s Lake, Wisconsin. Note that neither of these is in the UK airspace.
I want to know which FPL causes this problem ?
It can help me to understand.
According to https://chaos.social/@russss/111048524540643971, it was FBU (French Bee) 731 from LAX/KLAX to ORY/LFPO. It passed two waypoints called DVL on its expanded flight plan: Devil’s Lake, Wisconsin, US, and Deauville, Normandy, FR (an intermediate on airway UN859).
Flightaware link in the post.
Thanks, I was just coming here to post that.
https://www.flightaware.com/live/flight/FBU731/history/20230828/0255Z/KLAX/LFPO
So not even a five-character fix which you might naïvely expect to be unique, a three-character navaid.
Why the NATS system cannot recognize point ‘SITET’ on FIR boundary? Its hard to think about…
NATS does recognize SITET as the boundary in the ADEXP flight plan. The problem is that the pilot doesn’t know this, as the ICAO4444 flight plan simply says GWC UN859 LGL (fly from Chichester to L’Aigle via route UN859).
NATS needs to figure out which waypoint the pilot thinks is the first waypoint outside UK airspace (that’s LGL).
Starting with SITET, the software program now looks if SITET is on the pilot’s flight plan. It’s not.
The program now moves from SITET to next ADEXP waypoint, which is ETRAT. Is that on the pilot’s flight plan? It’s not.
The program now moved from ETRAT to the next ADEXP waypoint, which is DVL. Is that on the pilot’s flight plan? Yes, it is!
The software now thinks that the UK portion of the ICAO4444 flight plan is between KESIX (?), north-west of Ireland, and DVL. But when it is trying to identify that portion, it starts with KESIX and then reads up to the end of the flight plan without having found DVL, because DVL is in America, before KESIX in the flight plan route, and not after it.
The software is now stuck. It has a function to tell it the first ICAO4444 waypoint on the route outside the UK, but it can’t find that exit point on the ICAO4444 flight plan. Something has gone wrong, and nobody anticipated that this could go wrong. None of the people who designed and programmed this system had understood that this could fail: the function had returned a waypoint that was sure to be on the ICAO4444 flight plan, so the program should always find it.
And when it couldn’t, it shut itself down.
If I’m understanding your steps correctly, it sounds like NATS doesn’t “know” that the UK system (ADEXP) adds waypoints. Is the NATS software customized? If so, the designers screwed up seriously. If not, I’m surprised this problem didn’t appear before; does no other national/regional system add waypoints? (IIRC, an illustration in Haydon’s article suggests some do.)
The final report, whenever UK authorities get around to it, will be very interesting; one wonders whether they’ll dare to declare a sole supplier to be at fault, and if so whether there will be penalties.
@CHip:
Some terminology:
NATS Plc is the company that runs UK air traffic services.
ADEXP is a flight plan format. Eurocontrol sends NATS flight plans in this format. The ADEXP data contains a copy of the original, ICAO4444-formatted flight plan, and adds its own, more detailed description of the filed route.
The system that converts the ADEXP flight plan to the UK NAS’s national format is called FPRSA-R. The system does know that the ADEXP route has more waypoints; that’s why it has the procedure that went wrong. The system is set up to deal with that, and had processed over 15 million flight plans before the incident. This should tell you that the designers did a pretty good job in general.
That sounds like a case for multinaming as is now done for airports (e.g., the routing was from LAX/KLAX); waypoints that a country is responsible for making unique within its boundaries should have a country identifier prepended, to make them unique worldwide. But I have no idea how hard this would be to implement either in naming or in software — there may be places in some countries’ ATC code that only allow 3 letters for an ID.
https://jameshaydon.github.io/nats-fail/ (from the chaos.social link Rob provides) goes into more detail than I can easily follow about how the process works, but it’s clear that Haydon sees the same issues with the code behavior that we do (e.g., dreadful exception handling), along with another I didn’t think of before: why was the process that extracted the UK portion of the flight looking so far away from the UK that it even noticed DVL-in-the-US at all? Haydon describes a more plausible algorithm that wouldn’t have failed because it wouldn’t have looked at vast tracts of irrelevant flight path — which seems an obvious mistake once the coder realizes that there may be two waypoints of the same name provided they’re far enough apart. Haydon also notes that the 1-in-15-million isn’t so impressive a figure when converted to a real-world calendar: the system had been running this code for 5 years, which is rather too short an interval for a periodic system failure — and in interval that is likely to get shorter as air traffic increases. (Consider that much of that 5-year interval was during COVID….)
I’d hate to be the pilot responsible for filing that flight plan. Mind you, I guess it’s better than having an 8cm worm in my brain! 😱